만약 같은 테이블을 다른 entity 로 논리적으로 분리하게 되면 1차 캐시가 동작할까? 라는 질문으로부터 1차캐시가 어떻게 동작하는지 궁금해졌다.
실제 1차 캐시가 동작하는 방식은 더 복잡하고, 연관관계가 있는 경우에는 또 다르게 동작한다. 그렇기에 해당 포스트에서는 연관관계가 없는 단일 테이블 조회에서 1차 캐시가 어떻게 동작하는지 살펴보고자 한다.
1차 캐시란 무엇인가?
우선 1차 캐시가 정확히 무엇인가? 라는 질문을 해야한다.
JPA 에서 1차 캐시는 영속성 컨텍스트(Persistence Context) 를 의미한다.
어플리케이션은 엔티티를 엔티티 매니저 를 통해 다루게 된다.
즉, 엔티티 매니저를 통해 entity 의 상태 (managed, detached, removed 등) 을 관리하게 된다.

그리고 이 엔티티 매니저 는 영속성 컨텍스트 를 통해, 트랜잭션마다 엔티티 관리를 하게 된다.
PersistenceContext 인터페이스를 구현한 객체는 내부적으로 Map 객체에 entity 를 저장하고 있다.
일반적으로 OSIV 를 사용하지 않는다고 가정하면, 1차 캐시는 트랜잭션이 생성될 시점에 생성하고, 트랜잭션이 끝날 때 제거된다.
케이스 살펴보기
그렇다면, 1차 캐시는 언제 어떻게 동작할까? 우선적으로 케이스 여러개를 살펴보고자 한다.
- transaction X
- transaction O
- pk 조회
- column 조회
- 같은 table 다른 entity 로 조회
1. transaction 이 없는 경우
- select 쿼리 O
transaction 이 없는 경우, 조회 시점에 영속성 컨텍스트에 데이터가 없기 때문에 select 쿼리가 한번 더 나가게 된다.
@Service
class TestService(
private val testRepository: TestRepository
) {
fun test() {
val save = testRepository.save(TestEntity.of("test"))
val found = testRepository.findByIdOrNull(save.id!!) ?: throw RuntimeException("not found")
println("[FOUND] $found")
}
}
2. transaction 이 있는 경우
- select 쿼리 X
save 호출시 영속성 컨텍스트에 entity 를 저장한다.
그리고 transaction이 아직 열려있기 때문에, 영속성 컨텍스트가 남아있어서 조회시점에도 영속성 컨텍스트를 통해 조회가 가능하다. 따라서, 실제 database에 조회하지 않는다.
@Service
class TestService(
private val testRepository: TestRepository
) {
@Transactional
fun test() {
val save = testRepository.save(TestEntity.of("test"))
val found = testRepository.findByIdOrNull(save.id!!) ?: throw RuntimeException("not found")
println("[FOUND] $found")
}
}
3. id 가 아닌 조건으로 조회를 한다면?
- select 쿼리 O
id 가 아니라 다른 조회 조건을 통해 조회한다면 역시 select 쿼리가 나가게 된다.
아래의 예시의 경우 당연히 “test” 라는 이름의 레코드가 유니크하지 않을 수 있으니, 조회하는게 당연해보인다.
하지만 유니크 인덱스 정보를 준다고해도, 쿼리가 나간다.
@Service
class TestService(
private val testRepository: TestRepository
) {
fun test() {
val save = testRepository.save(TestEntity.of("test"))
testRepository.findByName("test") ?: throw RuntimeException("not found")
println(save)
}
}
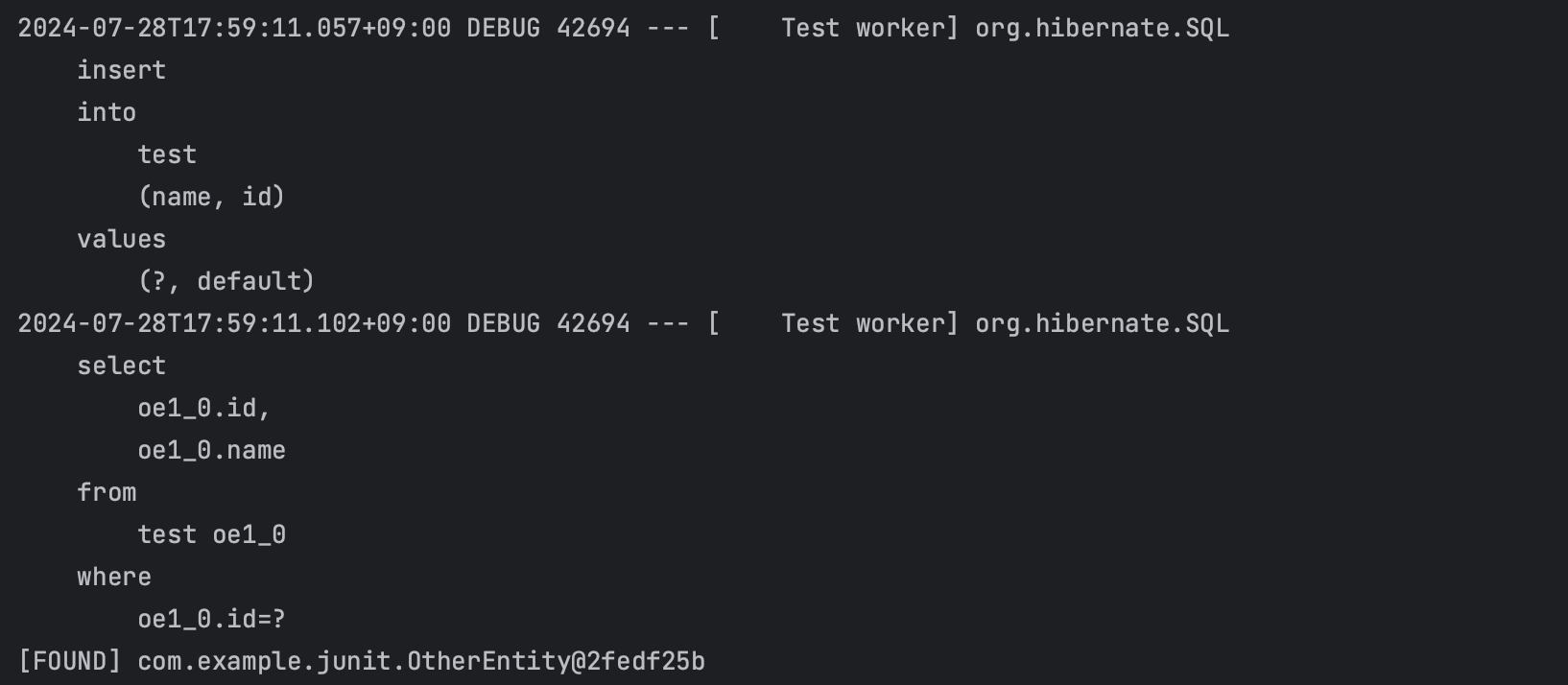
4. 같은 테이블을 다른 entity 로 분리한다면?
- select 쿼리 O
아래의 코드처럼 같은 테이블을 논리적으로 다른 entity 로 다루게 된다면 어떻게 될까?
이 경우에도 select 쿼리가 나간다.
@Entity
@Table(name = "test")
data class TestEntity private constructor(
val name: String
) : BaseEntity()
@Entity
@Table(name = "test")
class OtherEntity(
val name: String
) : BaseEntity()
@Service
class TestService(
private val testRepository: TestRepository,
private val otherRepository: OtherRepository
) {
@Transactional
fun test() {
val save = testRepository.save(TestEntity.of("test"))
val found = otherRepository.findByIdOrNull(save.id!!) ?: throw IllegalStateException("Not found")
println("[FOUND] $found")
}
}
1차 캐시를 조회하는 조건
그렇다면, 언제 1차 캐시를 통해 조회할까?
간단하게 요약하자면, 1차 캐시를 통해 entity를 로드하는 조건은 아래와 같다.
- 영속성 컨텍스트가 있고, pk 를 통해 entity 를 조회한다.
- entity 가 managed 상태여야한다.
- entity 객체가 같아야한다.
내부적으로는 조금 복잡하게 동작하는데, 전체적으로는 아래의 플로우를 통해 조회를 하게된다.
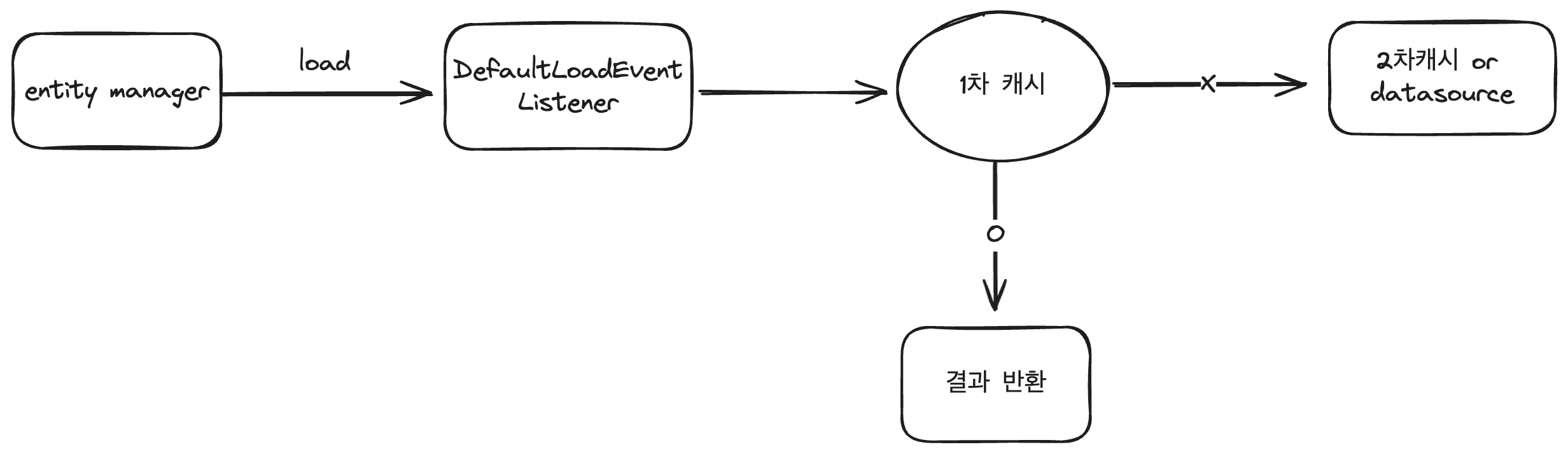
플로우 상에 1차 캐시 조회는 EntityKey 라는 객체로 1차 캐시에 존재 여부를 확인한다.
이때 EntityKey 는 아래 조합으로 구성된다.
- id
- entity 객체의 클래스 타입
// 영속성 컨텍스트(1차 캐시) 의 구현체
public class StatefulPersistenceContext {
private HashMap<EntityKey,
StatefulPersistenceContext.EntityHolderImpl> entitiesByKey;
}
3번 4번 케이스에 대한 해설
3번처럼 Spring Data Jpa 로 메서드를 생성하는 경우, 실제로는 내부적으로 JPQL 을 생성하여 호출하게 된다.
이 과정에서 영속성 컨텍스트를 찾는 과정 자체가 없다. 그렇기 때문에, select 쿼리가 추가로 생성된다.
4번 케이스의 경우, id 를 통해 조회하였음에도 불구하고 entity class 자체가 다르기 때문에 영속성 컨텍스트를 통해 찾을 수 없다.
4번 케이스의 경우, 영속성 컨텍스트에는 데이터베이스에서 가져온 레코드를 저장하는게 아니라, 객체가 저장되기 때문에 논리적으로 entity 를 다르게 매핑한다면 내부적으로 타입자체가 다르기 때문에 조회가 불가능한게 당연하다.
'스프링부트' 카테고리의 다른 글
| @Async 를 통해 비동기 호출을 해보자 (1) | 2024.11.10 |
|---|---|
| 스프링부트 테스트(2) - configuration 과 property (1) | 2024.07.23 |
| 스프링부트 테스트(1) - 동작원리와 어노테이션 친해지기 (1) | 2024.07.23 |
| AOP 활용 (feat. jpa 호출 로깅) (0) | 2024.06.06 |
| 스프링 AOP - 톺아보기 (1) | 2024.06.06 |

