Redis 복제(Replication) 기초
HA(High Availability)를 위해서는 아래 두가지가 필요하다
- 복제
- 자동 fail over
이번 글에서는 그중 Redis의 복제 개념을 먼저 살펴보고, 자동 Failover에 대해서는 Sentinel이나 Cluster에서 다루려고 한다.
1. 복제란
redis 노드는 크게 두 가지 역할을 가진다.
- master
- replica
Replica는 Master 노드의 데이터를 복사받아, **읽기 전용(read-only)**역할을 수행하며, 쓰기 커맨드는 기본적으로 Replica에서 불가능하다.
(물론 설정을 변경해 Replica에도 쓰기가 가능하게 할 수는 있지만, 권장하지 않는다.)
Redis 는 다른 DB 들과 달리 master 노드는 replica 가 될 수 없다.
1.1 복제의 동작 방식
Redis는 싱글 스레드로 클라이언트 요청(쿼리)을 처리하지만, 복제 작업은 Non-blocking 방식으로 진행된다.
- 복제가 진행되는 동안에도 Master는 계속 클라이언트 요청을 처리할 수 있다.
Replica 쪽도 대부분의 경우 비동기로 동작하지만,
- 초기 동기화(특히 전체 복제를 받는 과정)에서 일시적으로 클라이언트를 차단할 수 있다.
- 초기 동기화 이후 데이터 로드는 메인 스레드에서 이루어져서 짧은 시간 동안 쿼리가 차단된다.
1.2 복제 흐름

- 클라이언트는 Master에 명령을 보내고, Master로부터 응답을 받는다.
- 이때, 동시에 Replica로의 복제(동기화)가 완료될 때까지 클라이언트가 기다리지 않는다.
- 즉, Master로부터 응답을 받은 시점에 Replica에는 해당 명령이 수행되지 않았을 수 있다. 이를 Replication Lag라고 부르며, 짧은 시간 동안 Master와 Replica가 다른 데이터 셋을 가질 수 있다.
- Replica와의 연결이 끊어지면, 부분 재동기화(Partial Resynchronization)를 시도한다.
- 부분 재동기화가 불가능한 경우, 전체 재동기화(Full Resynchronization)를 요청한다.
2. 동기화
- Replica가 Master에 접속하여 “PSYNC”를 요청합니다.
- Master는 Replica가 완전한 데이터 동기화가 필요한 “Full Sync” 상태라고 판단하면,
- 내부에서 **fork()**를 실행해 백그라운드(child) 프로세스를 생성합니다.
- 그 자식 프로세스가 RDB 스냅샷(디스크 기반) 혹은 diskless 복제(네트워크로 바로 전달) 데이터를 만들어서 Replica로 보냅니다.
- 이때 fork() 때문에 Copy-on-Write(COW) 오버헤드가 발생합니다.
이 과정을 통해 Master는 큰 부하 없이도 병렬로 스냅샷을 떠서 Replica로 전송할 수 있는데, 문제는 fork 시점에 OS 수준에서 메모리를 복사(혹은 COW)에 대한 비용이 들거나, RDB 파일을 디스크에 쓸 경우 I/O 부담이 생길 수 있다.
2.1 전체 동기화
전체 동기화는 Replica가 Master의 전체 데이터를 복제하는 것을 의미한다.
보통 아래 두 상황에서 발생한다.
- Initial Synchronization: Replica가 Master에 최초로 커넥션을 맺을 때.
- Full Resynchronization: Replica가 Master와 다시 커넥션을 맺을때, 일부 데이터만으로는 동기화를 맞출 수 없을 때. 즉, 백로그 기반 부분 재동기화가 불가능할 때.
전체 동기화 방법은 크게 두 가지이다.
- 디스크 사용 (Disk-based)
- 디스크 사용 X (Diskless)
2.1.1 디스크 사용 (Disk-based)
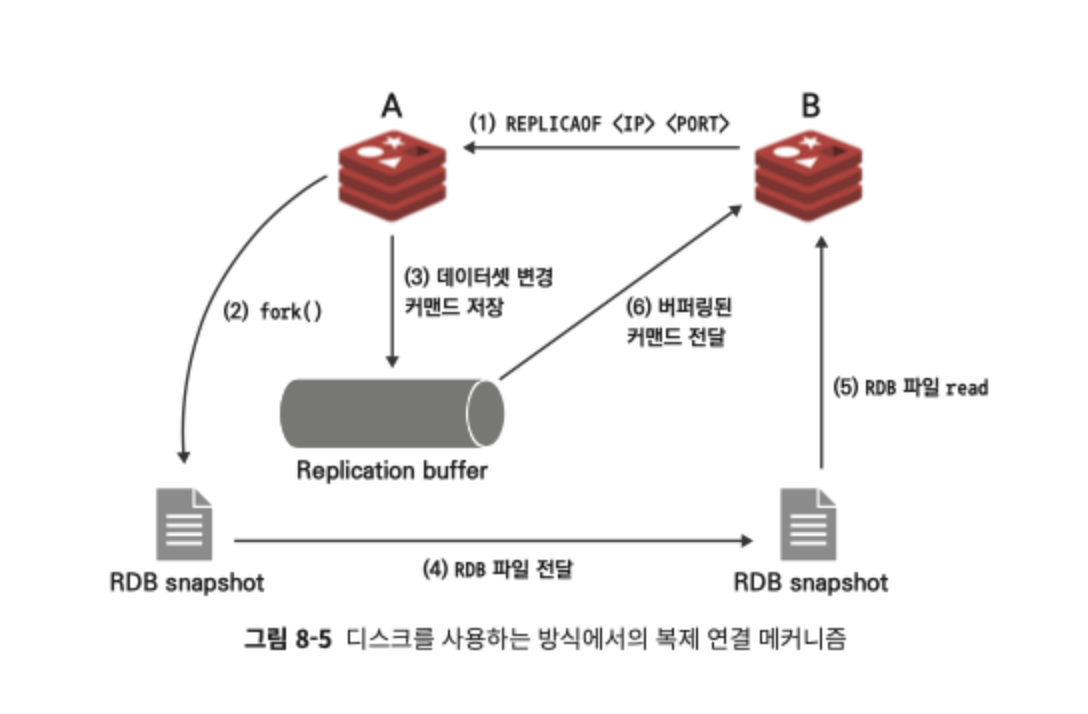
- Master가 백그라운드에서 fork로 자식 프로세스 생성
- 자식 프로세스가 RDB 파일을 디스크에 생성
- RDB 파일을 Replica 에 전달
- Replica 에서 RDB 파일 메모리에 로드
- RDB 생성 시점 이후 Master 가 처리한 명령(버퍼링된 명령어) 를 Replica에 전달하여 최신 상태로 맞춤
2.1.2 디스크 사용 X (Diskless)

느린 디스크의 경우, RDB 파일 생성하는 것은 마스터 노드 자원에 부담을 준다.
마스터 노드가 디스크 사용하지 않는 경우는 아래처럼 동작한다.
- fork 된 자식 프로세스가 소켓 통신을 통해서 replica 에게 데이터를 전송
- replica 가 이를 RDB 파일로 dlatl 저장
- 기존 메모리 flush 후 데이터 로드
- 마스터가 버퍼링 해둔 커맨드를 전달하여 동기화
참고로 전체 동기화시에는 fork 로 인해 Copy-on-Write 오버헤드가 발생한다.
AWS의 ElasticCache 를 사용하는 경우 forkless 로 동작한다.
정확한 내부 동작은 나도 모름.
디스크를 쓰지 않으므로 전체 I/O 부담이 줄어들지만, Disk-based 복제처럼 이미 만들어진 RDB 파일을 여러 Replica가 동시에 공유할 수 없다.
Disk-based 방식은 복제 진행 중 다른 replica 가 복제 연결시
해당 연결이 큐에 저장되어 있다가, 파일 저장 완료되면 여러 replica 에 복제본을 줄 수 있다.
반면, diskless 방식은 repl-diskless-sync-delay 옵션을 통해서 복제 요청시 일정시간 기다렸다가,
해당 시간내에 다른 복제요청이 오면 한번에 같이 보내는 식으로 동작할 수 있다.
Redis 7 버전 이후에는 기본 설정(repl-diskless-sync = yes)이 Diskless 방식으로 바뀌었다.
참고: Diskless라고 해서 fork()를 하지 않는 것은 아니다. Redis는 기본적으로 복제 시 백그라운드 프로세스를 만들어 데이터를 전송하며, 그 과정에서 fork()로 인한 COW가 어느 정도 발생할 수 있으나, disk 를 사용하지 않기 때문에 I/O 비용을 줄일 수 있다.
다만, AWS ElastiCache 등 매니지드 서비스에서는 내부적으로 “forkless” 최적화를 적용해, 사용자가 체감하는 COW 비용을 최소화하기도 합니다.
2.2 부분 재동기화
Redis는 노드에 replica 가 연결되면, Replication backlog라는 메모리 공간을 할당한다.
이는 부분 재동기화를 위한 것으로 일정 시점 이전까지의 커맨드를 저장하고 있다.
그리고 Replica 는 연결될 때 master의 replica id 와 replica offset 정보를 통해
어떤 master에 연결되었는지, 어디까지 명령 복제가 되었는지 정보를 저장한다.
이 정보를 통해 부분 재동기화가 가능하다.
- Replica가 Master와 연결이 끊어지면 자동으로 재연결을 시도한다. 이 때, 이미 받은 시점(Offset) 이후의 명령만 백로그에서 꺼내 보내주면 된다.
- 이를 부분 재동기화라고 부르며, 전체 복제를 재시도하지 않아도 되는 이점이 있다.
만약 Replica가 알고 있는 Master의 replication id나 offset 정보가 Master와 불일치하거나,
백로그에 보관된 양보다 더 많은 데이터가 필요하다면, 전체 동기화를 진행한다.
2.3 replication id, offset
- replication id: 현재 Master 데이터 셋에 대한 히스토리
- offset: 해당 히스토리의 서로 다른 시점에 대한 표기이다. (같은 데이터 셋이라고 해도, 복제에 따라 서로 다른 시점의 데이터를 가질 수 있음을 의미한다. 즉, 최신의 데이터가 무엇인지 파악하기 위한 논리적 시점)
Master 가 바뀌어서 replica 중 하나가 Master 로 승격시에도, 이전의 Master ID 를 저장해두는데 이것을
secondary replication id 라고 한다.
이를 통해, fail over 가 발생하여 새 Master 승격되어도, Replica 사이에 기존 Master 히스토리가 같은지 확인하여, 부분 재동기화를 진행할 수 있게 된다.
(만약 기존 replication id 가 없다면 전체 재동기화를 해야할지도 모른다)
3. 복제시 유의 사항
3.1 replica 는 기본적으로 read-only
Replica 는 기본적으로 쓰기 커맨드가 비활성화 되어있다. 물론 해당 설정은 해제가 가능하나, replica 에 직접 데이터를 쓰는 경우는 권장되지 않는다. 왜냐하면,
- 재동기화 시 데이터 유실 가능성이 있고,
- replica 에 직접 쓰여진 데이터는 하위 replica 로는 전파되지 않는다.
3.2 Persistence 와 함께 사용하기
replica 기능을 사용할 때, 데이터 백업 기능(Persistence)을 사용하는 것이 좋다.
백업 (persistence) 기능을 사용하지 않을거라면 재부팅시 재시작하지 않도록 설정해야한다.
그렇지 않으면 Master 노드가 재부팅 후 재시작하면서 빈 데이터셋을 Replica 에 전달하여, 데이터가 모두 제거될 수 있다.
참고로, 센티널이나 클러스터를 사용하는 경우 자동 fail over 를 통해 replica 에서 master 로 승격이 진행되나,
replica 만 사용하는 경우에는 자동으로 fail over 되지 않는다.
'데이터베이스' 카테고리의 다른 글
| redis - pub/sub 동작 원리 (0) | 2024.11.18 |
|---|---|
| MySQL(InnoDB)이 잠금할 레코드를 고르는 방법 (1) | 2024.06.05 |
| redis lock 1부 (feat. Redlock) (0) | 2024.05.03 |
| 왜 많은 회사들은 READ COMMITTED를 사용할까? (0) | 2023.07.07 |



